搜索结果
Powered by: Simple-Jekyll-Search
https://ar5iv.labs.arxiv.org/html/2308.10425
![[神经网络]Extra 02 STAEformer学习笔记](/images/default_cover.webp)
上网搜了搜,似乎关于这篇论文的资料比较少,于是自己啃了啃论文,看了看源代码,并斗胆分享一下自己的理解。
直接开门见山地说吧,我就是来推荐一个插件的:沉浸式翻译,如果你已经在用了或者不感兴趣,那么请直接跳过这一小节。

先聊一些简单的东西:如果你对监督学习有些了解的话,应当知道我们需要一些东西来评估模型好不好。对于判别模型的话,通常有一些评价指标,比如准确率、精确率、召回率等等,而对于回归模型,我们通常会将模型的预测值与真实值进行比较,从而得出模型的好坏。在这篇论文中,模型用于预测交通流量,属于回归类问题,所以我们需要一些回归类的评价指标,下面介绍的几种就是常用的回归类评价指标。
MAE (Mean Absolute Error) - 平均绝对误差
mean_absolute_error函数,函数原型为:def mean_absolute_error(y_true, y_pred, *, sample_weight=None, multioutput="uniform_average")
MAPE (Mean Absolute Percentage Error) - 平均绝对百分比误差
sklearn提供了计算MAPE的函数mean_absolute_percentage_error,函数原型为:def mean_absolute_percentage_error(y_true, y_pred, *, sample_weight=None, multioutput="uniform_average")
RMSE (Root Mean Square Error) - 均方根误差
sklearn,提供了计算RMSE的函数mean_squared_error,函数原型为:def root_mean_squared_error(y_true, y_pred, *, sample_weight=None, multioutput="uniform_average")
该论文采用了诸多数据集进行验证,但这些数据集的采集间隔、特征维度等信息都基本一样,仅在传感器数和时间戳数上有所不同。下面仅介绍一下PeMS08,其他数据集与该数据集类似。
npz,采用float32存储。
| 数据集 | 传感器数 | 时间戳数 | 时间范围 |
|---|---|---|---|
| METR-LA | 207 | 34272 | 2012/03-2012/06 |
| PeMS-BAY | 325 | 52116 | 2017/01-2017/05 |
| PeMS03 | 358 | 26209 | 2012/05-2012/07 |
| PeMS04 | 307 | 16992 | 2018/01-2018/02 |
| PeMS07 | 883 | 28224 | 2017/05-2017/08 |
| PeMS08 | 170 | 17856 | 2016/07-2016/08 |
原始论文可以在arXiv[4]上找到。
为了保持简洁因为我懒,这里只简单介绍一下论文的主要内容,原文中CCS CONCEPTS、KEYWORDS等与内容关系不太大的部分就不介绍了,之后按照论文的行文顺序,逐一介绍各部分内容。
摘要部分作者写的很短,主要是介绍了该研究领域的困境,并简单介绍了他们提出的新组件的效果。

结合下文作者提出的新组件和他们的创新点,颇有种“众人皆醉我独醒”的感觉。
在本节,作者介绍了先前的一些工作,以及他们的工作的创新点。
我觉得这是非常正确的,模型的结构决定了模型表达能力的上限,但是模型的实际表现和数据(特征)的表示同样有着密切的关系。在模型结构如何改进都无法带来性能提升的情况下,说明限制模型效果的瓶颈可能已经不在于模型的表达能力上了。
“Notably, STID is among the few studies that explore these embeddings. It employs spatial embedding and temporal periodicity embedding with a simple Multi-layer Perceptron (MLP) and achieves remarkable performance.”
“值得一提的是,STID是少数探索嵌入的研究之一,它在一个简单的多层感知机上采用了空间嵌入和时间周期嵌入,并取得了显著的性能。”
然而就是似乎这么简单的结构却取得了SOTA的性能,也算说明了笔者的观点:在嵌入表示方面还有很大的提升空间。
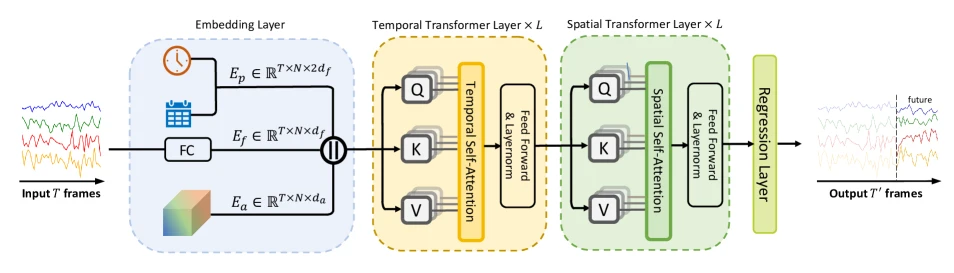
这一节直接介绍嵌入层,也包含本文主要的创新点:时空自适应嵌入。
为什么偏偏是这个时间和这个星期呢?因为我在写这一部分时就是5月24日的16:50,星期六….
index范围为$[0,6]$,时间戳的index范围为$[0,287]$(上文已对该类数据集做过介绍,每天会产生$288$个时间戳)。随后,作者构建了星期嵌入字典$T_w \in \mathbb{R}^{N_w \times d_f}$和时间戳嵌入字典$T_d \in \mathbb{R}^{N_t \times d_f}$,其中$N_w=7$,$N_t=288$。而$d_f$在此处表示周期嵌入的维度(没错,星期和时间戳嵌入的维度也是$d_f$)。index为2,时间戳的index为142,(此时可认为$t$时刻为星期三的11:00),该时刻的星期嵌入为$T_w[2]$,时间戳嵌入为$T_d[142]$。On one hand, it’s intuitive that the temporal relation is not only decided by periodicity but also affected by the chronological order in the traffic time series. For example, a time frame in traffic time series should be more similar to the time frames nearby. On the other hand, the time series from different sensors tend to have different temporal patterns. Thus, instead of adopting a pre-defined or dynamic adjacency matrix for spatial relation modeling, we designed a spatio-temporal adaptive embedding $E_a \in \mathbb{R}^{T \times N \times d_a}$ to capture intricate spatio-temporal relation in a uniform way. In particular, $E_a$ is shared across different traffic time series.
一方面,直观地说,时间关系不仅由周期性决定,而且还受到交通时间序列中时间顺序的影响。例如,交通时间序列中的时间范围应该与附近的时间范围更相似。另一方面,来自不同传感器的时间序列往往具有不同的时间模式。因此,我们没有采用预定义或动态邻接矩阵进行空间关系建模,而是设计了时空自适应嵌入$E_a \in \mathbb{R}^{T \times N \times d_a}$来以统一的方式捕获复杂的时空关系。特别是,$E_a$在不同的流量时间序列之间共享。
可能是考虑到这部分内容并不重点,作者将模型的其他部分全都放在了这一节,包括Transformer层和回归层。

Datasets. Our method is verified on six traffic forecasting benchmarks, i.e., METR-LA, PEMS-BAY, PEMS03, PEMS04, PEMS07, and PEMS08. The first two datasets were proposed by DCRNN (Li et al., 2018). The last four datasets were proposed by STSGCN (Song et al., 2020). The time interval in the six datasets is 5 minutes, so there are 12 frames in each hour. More details are shown in Table 2.
数据集。我们的方法在六个流量预测基准上进行了验证,即 METR-LA、PEMS-BAY、PEMS03、PEMS04、PEMS07 和 PEMS08。前两个数据集由 DCRNN(Li et al., 2018)提出。最后四个数据集由 STSGCN(Song et al., 2020)提出。六个数据集的时间间隔为 5 分钟,因此每小时有 12 帧。更多详细信息如表 2 所示。
Implementation. We implement the model with the PyTorch toolkit on a Linux server with a GeForce RTX 3090 GPU. METR-LA and PEMS-BAY are divided into the training, validation, and test sets in a fraction of 7:1:2. PEMS03, PEMS04, PEMS07 and PEMS08 are divided in a fraction of 6:2:2. In fact, the performance of our model is not sensitive to the hyper-parameters. For more details, the embedding dimension $d_f$ is 24 and the $d_a$ is 80. The number of layers $L$ is 3 for both spatial and temporal transformers. The number of heads is 4. We set the input and prediction length to be 1 hour, namely, $T=T’$ =12. Adam is chosen as the optimizer with the learning rate decaying from 0.001, and the batch size is 16. We apply an early-stop mechanism if the validation error converges within 30 continuous steps. The code is available at https://github.com/XDZhelheim/STAEformer.
执行。我们使用 PyTorch 工具包在配备 GeForce RTX 3090 GPU 的 Linux 服务器上实现该模型。 METR-LA 和 PEMS-BAY 按 7:1:2 的比例分为训练集、验证集和测试集。 PEMS03、PEMS04、PEMS07 和 PEMS08 被分成 6:2:2 的分数。事实上,我们模型的性能对超参数并不敏感。有关更多详细信息,嵌入维度 $d_f$ 为 24, $d_a$ 为 80。空间和时间Transformer的层数 $L$ 均为 3。头数为4。我们设置输入和预测长度为1小时,即 $T=T’$ =12。 Adam 被选为优化器,学习率从 0.001 开始衰减,批量大小为 16。如果验证误差在 30 个连续步骤内收敛,我们将应用提前停止机制。代码可在 https://github.com/XDZhelheim/STAEformer 获取。
Metrics. We use three widely used metrics for traffic forecasting task, i.e, $MAE$, $RMSE$ and $MAPE$. Following previous work, we select the average performance of all predicted 12 horizons on the PEMS03, PEMS04, PEMS07 and PEMS08 datasets. To evaluate the METR-LA and PEMS-BAY datasets, we compare the performance on horizon 3, 6 and 12 (15, 30, and 60 min).
指标。我们使用三个广泛使用的指标来进行流量预测任务,即 $MAE$、$RMSE$ 和 $MAPE$。继之前的工作之后,我们选择了 PEMS03、PEMS04、PEMS07 和 PEMS08 数据集上所有预测的 12 个 horizons 的平均性能。为了评估 METR-LA 和 PEMS-BAY 数据集,我们比较了 3、6 和 12 个 horizon (15、30 和 60 分钟)的性能。
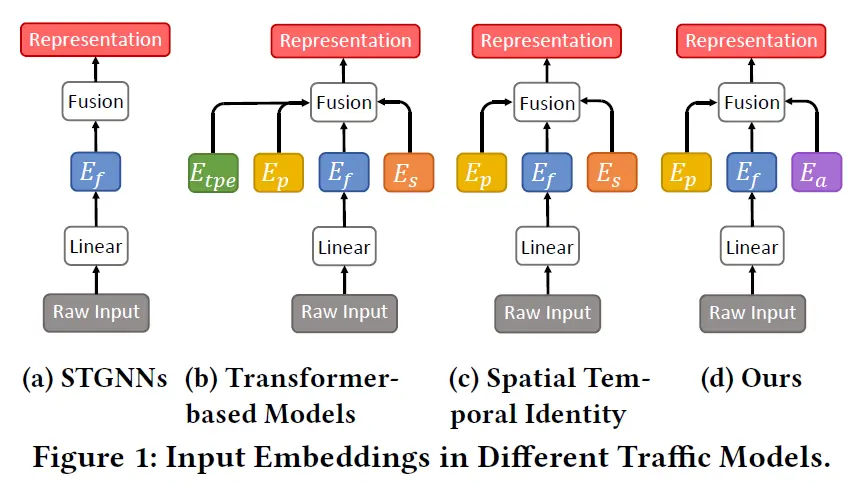
Baselines. In this study, we compare our proposed method against several widely used baselines in the field. HI (Cui et al., 2021) is a typical traditional model. We also consider STGNNs such as GWNet (Wu et al., 2019), DCRNN (Li et al., 2018), AGCRN (Bai et al., 2020), STGCN (Yu et al., 2018), GTS (Shang et al., 2021), and MTGNN (Wu et al., 2020), which employ the embeddings shown in Figure 1(a). Additionally, we examine STNorm (Deng et al., 2021), which focuses on factorizing traffic time series. While there exist Transformer-based methods for time series forecasting, such as Informer (Zhou et al., 2021), Pyraformer (Liu et al., 2021), FEDformer (Zhou et al., 2022), and Autoformer (Wu et al., 2021), they are not specially tailored for short-term traffic forecasting. Hence, we select GMAN (Zheng et al., 2020) and PDFormer (Jiang et al., 2023a), which are transformer models targeting the same task as ours. The input embeddings in GMAN (Zheng et al., 2020) and PDFormer (Jiang et al., 2023a) follow the configuration in Figure 1(b). Furthermore, we consider STID (Shao et al., 2022b), which enhances the spaito-temporal distinction in traffic time series by utilizing the input embedding depicted in Figure 1(c).
基线。在这项研究中,我们将我们提出的方法与该领域广泛使用的几种基线进行比较。 HI (Cui et al., 2021)是典型的传统模型。我们还考虑了 STGNNs,例如 GWNet (Wu et al., 2019)、DCRNN (Li et al., 2018)、AGCRN (Bai et al., 2020)、STGCN (Yu et al., 2018)、GTS (Shang et al., 2021) 和 MTGNN (Wu et al., 2020),它们采用图 1(a) 所示的嵌入。此外,我们还研究了 STNorm (Deng 等人,2021),它专注于分解流量时间序列。虽然存在基于 Transformer 的时间序列预测方法,例如 Informer (Zhou et al., 2021)、Pyraformer (Liu et al., 2021)、FEDformer (Zhou et al., 2022) 和 Autoformer (Wu et al., 2021) ,它们并不是专门为短期流量预测量身定制的。因此,我们选择 GMAN (Zheng et al., 2020) 和 PDFormer (Jiang et al., 2023a) ,它们是与我们的任务相同的 Transformer 模型。GMAN (Zheng et al., 2020) 和 PDFormer (Jiang et al., 2023a) 中的输入嵌入遵循图 1(b) 中的配置。此外,我们考虑 STID (Shao et al., 2022b) ,它通过利用图 1(c) 中所示的输入嵌入来增强流量时间序列的时空区别。


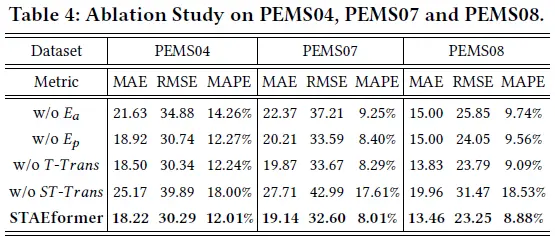
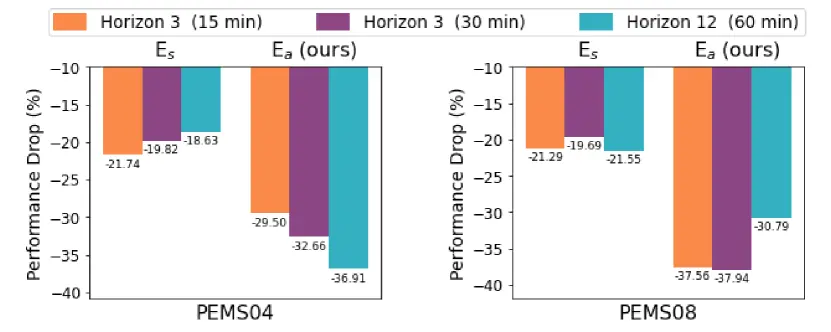
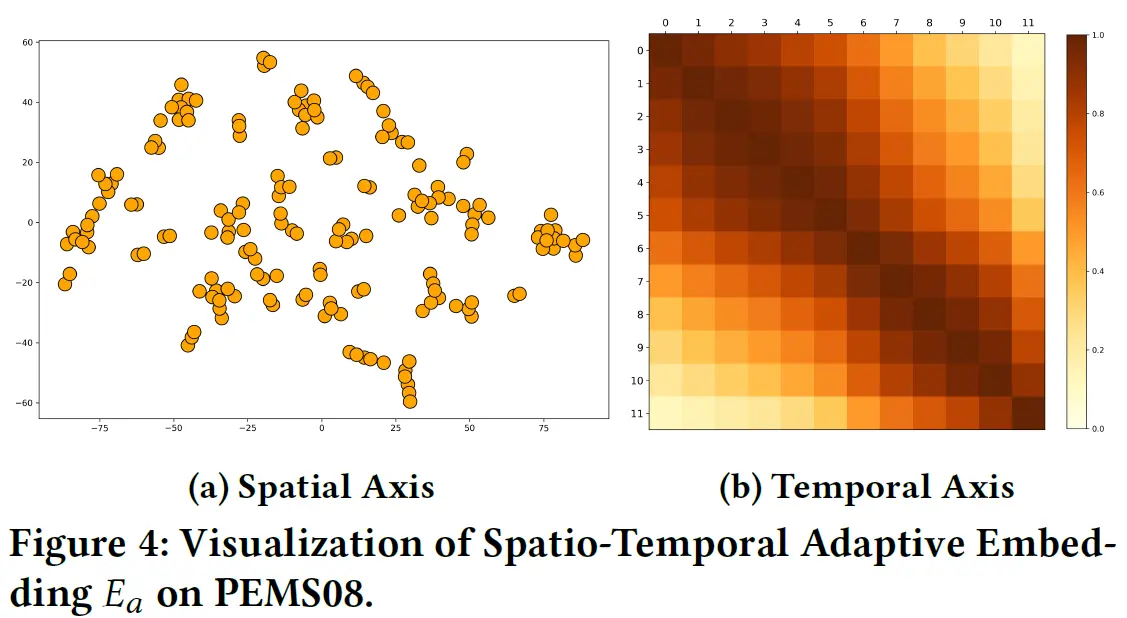
这篇论文的消融实验做的比较有意思,不仅有(常规的)移除组件后的效果对比,还进行了$E_a$的可视化。
为什么没有单独移除空间Transformer层的变体呢?我在PeMS08上移除$S-Trans$后发现甚至性能会有一定的提升…哈哈,这有点尴尬
是本文的主要参考资料